A interpretação da estatística frequentista - essa que todos estamos habituados a ler em artigos científicos nesta época, com valores p que precisam ser menores que um ponto de corte arbitrário de 5% (p < 0,05) é inadequada muito frequentemente. Isso já era previsto desde o Fihser, mas vamos deixar os detalhes da história da estatística para os estatísticos. Primeiro, os erros:
1- p > 0,05 ou maior que qualquer outro valor NÃO significa que não existe diferença entre os grupos.
2- p < 0,05 ou menor que qualquer outro valor NÃO significa que existe diferença entre os grupos.
Agora você pode estar em em um ou mais desses 3 grupos:
1-Não acredita em mim, acha que escrevi bobagem; ou
2-Acha que apenas revistas fracas cometem / permitem esse tipo de erro; ou
3-Sabe que estou certo.
Se está no grupo 1, recomendo a declaração da sociedade americana de estatística de 2016 (http://dx.doi.org/10.1080/00031305.2016.1154108) e veja a maior parte do que você achava que sabia sobre p-valores ser descartado.
Se está no grupo 2, veja o infonográfico desta edição da Anesthesiology:
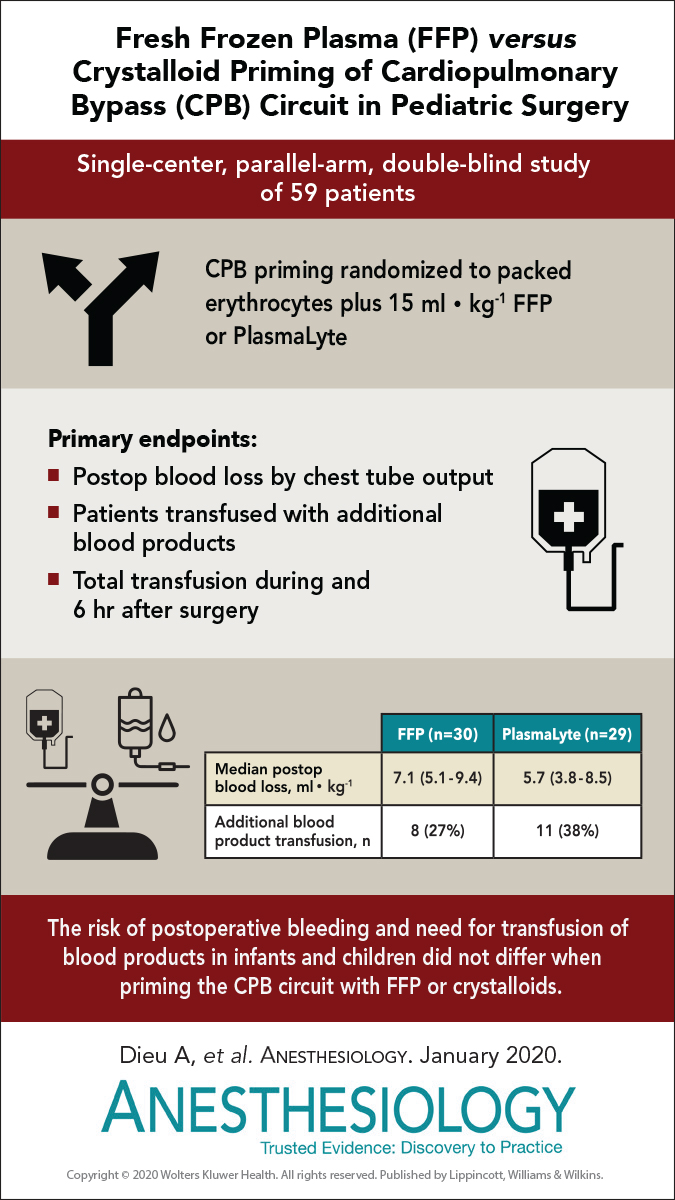 Veja a frase no vermelho: claro que houve diferença, mas como p>0,05 eles resolveram concluir que não foi diferente.
Veja a frase no vermelho: claro que houve diferença, mas como p>0,05 eles resolveram concluir que não foi diferente.
E finalmente, a dica:
Pense em casos extremos, sabendo que se o tamanho da amostra tender ao infinito, o valor p tende a zero.
Imagine que você quer saber se um tratamento (ondansetrona) é melhor que outro (placebo) para prevenção de náuseas pós-operatórias. Você faz um caso em cada grupo e nenhum paciente vomita. Acha justo concluir que não existe diferença entre os 2 grupos (ondansetrona e placebo)? Parece obvio que não, certo?
Mas quando posso concluir que não há diferença? Quando o grupo é grande e p ainda assim é > 0,05?
Resposta: NUNCA!
A estatística frequentista não serve para provar que duas coisas são iguais porque parte do pressuposto que são diferentes (mesmo que algumas vezes essa diferença seja bem pequena). Existe uma adaptação em que você determina uma faixa de equivalência aceitável e, com amostra suficiente, consegue concluir que a diferença entre os grupos é clinicamente insignificante - mas ainda é um método bem raro e sofisticado.
O outro extremo é igualmente importante e CUIDADO - estamos agora gerando enormes bancos de dados graças aos prontuários eletrônicos (Supostos BIG Datas, mas na verdade não são, explicarei em outra postagem). Isso significa que teremos muitos p-valores bem pequenos devido apenas ao tamanho da amostra e não à associação verdadeiramente forte entre os fatores. Não vou explicar o teorema do limite central, ficaria longo, mas acredite - p valor depende do tamanho da amostra, não apenas da diferença entre os grupos.
 orcid.org/0000-0001-6289-2233
orcid.org/0000-0001-6289-2233